本文共 1227 字,大约阅读时间需要 4 分钟。
2016年提出的
空洞卷积广泛应用于语义分割与目标检测等任务中
空洞卷积(膨胀卷积/扩张卷积) Dilated/Atrous Convolution
空洞卷积是一种不增加参数数量同时增加输出单元感受野的一种方法。Atrous 卷积,就是带洞的卷积,卷积核是稀疏的
空洞卷积的概念是从语义分割任务中发展出来的,是为了解决基于FCN思想的语义分割中,输出图像的size要求和输入图像的size一致而需要upsample,但由于FCN中使用pooling操作来增大感受野同时降低分辨率,导致upsample无法还原由于pooling导致的一些细节信息的损失的问题而提出的。为了减小这种损失,自然需要移除pooling层,因此空洞卷积应运而生。
原先的 CNN architecture 是用一个“实心”的 kernal 去扫描 input data,然后使用 pooling 方法直接暴力的删掉其余 75% 的信息量,只留下 25% 的原汁原味,这样的做法在还没有精确到 pixel-wise 的情况时还是可以行的通的,一旦要归类到小至 pixel 等级的尺度时,pooling 对原 data 的破坏力足以让事情搞砸,试想一个原始数据被经过 Convolution 剥离出了其区域特征后,接着下一个环节被大刀阔斧般的砍去内部信息,并且永久无法复原,小物体信息无法重建 (假设有四个pooling layer 则任何小于 2^4 = 16 pixel 的物体信息在理论上将无法重建和分割)。这是在微小的 pixel 世界中无法接受的做法。
如果说 pooling 这种简单删减 data 让单位 output 中 Receptive Field 增大的方法不可行,就需要一个新的在不删减原始数据的情况下,直接让 Receptive Field 提升的办法:Dilated Convolution。简单的说,就是把原本“实心”的 kernal 元素之间按照一定规律插入 0 元素作为空格
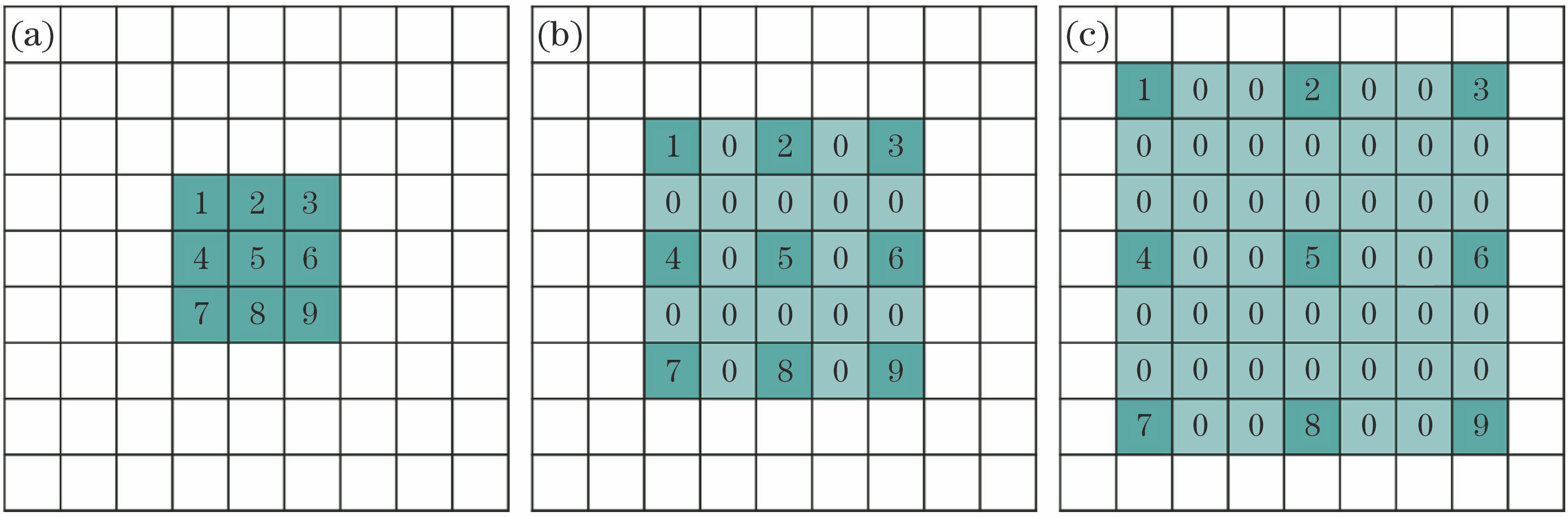
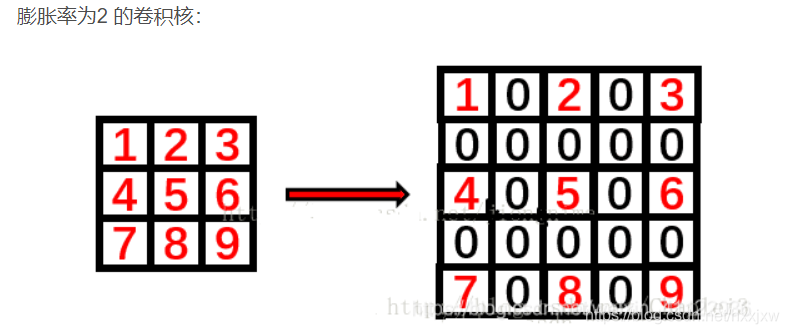
空洞卷积向卷积层引入了一个称为 “扩张率(dilation rate)”的新参数,该参数定义了卷积核处理数据时各值的间距。
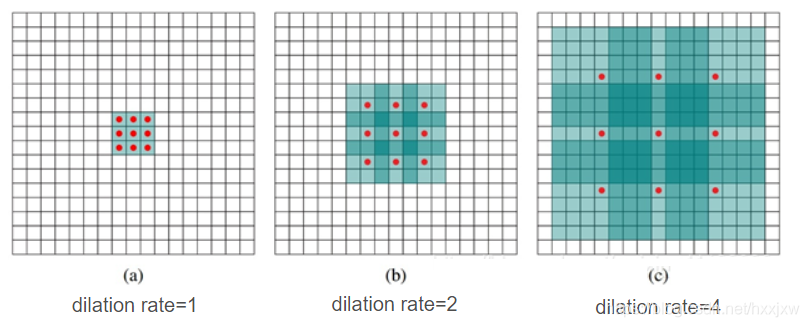
看下图可以对膨胀率有一个比较直观的理解
假设原始特征为feat0
首先使用扩张率为1的空洞卷积生成feat1,feat1上一点相对feat0感受野为3*3(如图a);
然后使用扩张率为2的空洞卷积处理feat1生成feat2(如图b),使第一次空洞卷积的卷积核大小等于第二次空洞卷积的一个像素点的感受野,图b即feat1上一个点综合了图a即feat0上3*3区域的信息,则生成的feat2感受野为7*7,即整个图b深色区域;
第三次处理同上,第二次空洞卷积的整个卷积核大小等于第三次空洞卷积的一个像素点的感受野,图c即feat2上每个点综合了feat0上7*7的信息(感受野),则采用扩张率为3的空洞卷积,生成的feat3每一个点感受野为15*15。